
TLDR: I reverse engineered the Teenage Engineering OP-1 drum patch so that I could make my own custom patches automatically. The website that resulted from this is teoperator.com.
I do not work at Teenage Engineering.
Nor do I know anything about audio file formats.
Despite this, I managed to reverse engineer one of the audio file formats for the OP-1 synthesizer, made by Teenage Engineering.
The end result is a nice little website that lets you build patches for the OP-1 sampler: https://teoperator.com. All the code I talk about here is open-source and also available on Github.
The rest of this blog is the story of how I got there.
too many words, too many samples
The OP-1 is a wonderful synthesizer capable of a great many things. One of the great things about it is a sampler, namely the Drum sampler engine. This sampler allows you to record a maximum 12 seconds of sound which can then be spliced between any two points. These splices can then be assigned to one of the 24 keys of the synth for easy playback. Normally the sampler is used for drums, but I like to use it for spoken word or poetry.
In fact, I like to use it for lots of spoken word and poetry. My last album had over 30 minutes of NASA recordings. My current album is sampling an hour of poetry readings. This ends up being hundreds of 12-second samples that need to be spliced and cut using the OP-1 Drum sampler engine.
For each 12-second sample I need to record it into the OP-1 via the line-in. Recording each one takes at least about a minute to set the levels and find the right position. After recording I work to splice it, which takes another minute or two. This is a easy workflow for a few 12-second samples. But for hundreds of 12-second samples, I’m looking at hours and hours of work.
I believe in this case that my time to program some software for this task is less than time of work of the task. ..which means: time to do some automation!
ffmpeg is magic
The first thing I do with a sample from file.mp3 is to convert it to the right OP-1 file type and truncate to 12 seconds (the max for the Drum sampler engine of the OP-1).
I know that the OP-1 has a special file type - the .aif file, which is popular for samplers. All I had to do was extract 12 seconds of audio and convert it into an .aif file. This is easily done with one ffmpeg command:
1ffmpeg -i file.mp3 -c copy -ss 00:00:00 -to 00:00:11.5 patch.aif
Next, to automatically generate key assignments I want to splice the sound. One way to splice is to use the transients, or when silence ends. Turns out that ffmpeg does this too! I wrote some code that runs ffmpeg for printing out places where it detects silence. The ffmpeg command for detecting silence, for file.mp3 for silence of at least 0.2 seconds at -22db is:
1ffmpeg -i patch.aif -af silencedetect=noise=-22db:d=0.2 -f null -
I can then use a fancy tool like audiowaveform to make an image of the waveform and use imagemagick to color code it so I can visualize the splicings. So a given segment of audio might look like this after splitting on the silence:
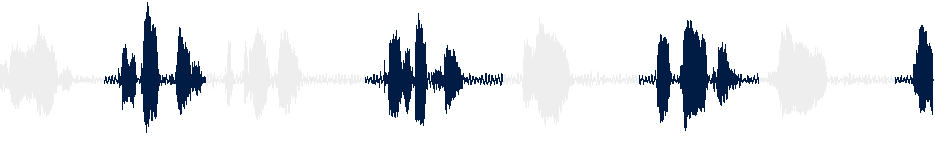
Great, now I have an OP-1 patch, patch.aif, that is the current length and format for uploading to the Drum engine sampler. The next step was to set the metadata of the patch.aif file so that it contains information that the OP-1 Drum sampler engine can use to assign the keys to each of the splices.
xxd to the rescue
The injection of metadata into my new patch.aif requires a bit of sleuthing/research because I don’t know how .aif files work. There is a file spec from 1988 but to be perfectly honest I found everything I need to know using the magic unix tool, xxd, and some second-rate guessing.
The xxd tool allows you to visualize a hexdump of any file. So I used it to look at a normal .aif file and compare it to a OP-1 .aif file (which I downloaded from the synthesizer).
The first 30 bytes from a normal non-OP-1 .aif file looks like this:
$ xxd file.aif | head -n 3
00000000: 464f 524d 0008 c4ee 4149 4646 434f 4d4d FORM....AIFFCOMM
00000010: 0000 0012 0002 0002 3130 0010 400e bb80 ........10..@...
00000020: 0000 0000 0000 5353 4e44 0008 c4c8 0000 ......SSND......
Obviously there are headers in the header (FORM,AIFF,COMM,SSND). I’m guessing that SSND is the PCM data. FORM seems special, because it has four bytes right after it. For that particular file, I converted those bytes to decimal (0008 c4ee) and they corresponded to the file size minus 8 bytes, so I assume it is just a file sizer.
Now here’s a truncated version of the OP-1 .aif file:
$ xxd op1.aif
00000000: 464f 524d 000f 4e6e 4149 4643 4656 4552 FORM..NnAIFCFVER
00000010: 0000 0004 a280 5140 434f 4d4d 0000 0040 ......Q@COMM...@
00000020: 0001 0007 a49c 0010 400e ac44 0000 0000 ........@..D....
00000030: 0000 736f 7774 2953 6967 6e65 6420 696e ..sowt)Signed in
00000040: 7465 6765 7220 286c 6974 746c 652d 656e teger (little-en
00000050: 6469 616e 2920 6c69 6e65 6172 2050 434d dian) linear PCM
00000060: 4150 504c 0000 04c6 6f70 2d31 7b22 6472 APPL....op-1{"dr
00000070: 756d 5f76 6572 7369 6f6e 223a 322c 2264 um_version":2,"d
...
000004f0: 3139 322c 3831 3932 2c38 3139 322c 3831 192,8192,8192,81
00000500: 3932 2c38 3139 322c 3831 3932 2c38 3139 92,8192,8192,819
00000510: 322c 3831 3932 2c38 3139 322c 3831 3932 2,8192,8192,8192
00000520: 2c38 3139 322c 3831 3932 5d7d 0a20 5353 ,8192,8192]}. SS
00000530: 4e44 000f 4940 0000 0000 0000 0000 0000 ND..I@..........
00000540: 0000 0000 f5ff e0ff bcff 90ff 57ff 14ff ............W...
You’ll see that its got an AIFC (compressed format) and not AIFF, but that won’t matter, since my ffmpeg converted ones aren’t compressed. The big difference is that there is some JSON data, following the APPL tag. There are four bytes after the APPL which again corresponded exactly to the size until the SSND tag. This looks easy enough, all I have to do is insert APPL, then four bytes of size, then op-1, then my JSON data - right before the SSND tag.
When I did that, though, I corrupted my OP-1 sounds a few times. So don’t do that! It turns out there are bytes right before the SSND tag and right after the JSON closing bracket that are important. In opening several OP-1 files I noticed sometimes it was 0a20 or sometimes just 0a. I theorized that maybe it needs to keep blocks consistent, probably in multiples of 4 (because otherwise you would only have 1 byte or 0, not 2 or 1).
That works! So, after injecting the OP-1 meta data you have to insert 0a or 20 until the total size of the file is a multiple of 4. (Maybe this is bullshit, someone please let me know).
op-1 meta data
Finally, now that I know how to inject OP-1 data into a .aif file I just have to figure out what the OP-1 data will be.
My inspection of the .aif files with xxd reveals that the OP-1 metadata itself looks like this:
1{
2 "drum_version": 2,
3 "type": "drum",
4 "name": "user",
5 "octave": 0,
6 "pitch": [6144, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
7 "start": [0, 35186754, 73270908, 193926863, 262863847, 282963028, 327734734, 374604417, 422374972, 456892160, 477153660, 548131809, 570661720, 597144106, 696446963, 726788489, 830413096, 918041142, 955370511, 1001935845, 1053265249, 1053265249, 1053265249, 1053265249],
8 "end": [35182696, 73266850, 193922805, 262859789, 282958970, 327730676, 374600359, 422370914, 456888102, 477149602, 548127751, 570657662, 597140048, 696442905, 726784431, 830409038, 918037084, 955366453, 1001931787, 1053261191, 1153253906, 1153253906, 1153253906, 1153253906],
9 "playmode": [8192, 16384, 8192, 8192, 8192, 8000, 8192, 8192, 16384, 8000, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192],
10 "reverse": [8192, 16384, 8192, 8192, 8192, 16384, 8192, 8192, 8192, 8192, 16384, 8192, 8192, 8192, 8192, 8192, 8192, 16384, 8192, 8192, 8192, 8192, 8192, 8192],
11 "volume": [9195, 8192, 5190, 8192, 8192, 4969, 8192, 8192, 16384, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192, 8192],
12 "dyna_env": [0, 8192, 0, 8192, 0, 0, 0, 0],
13 "fx_active": false,
14 "fx_type": "delay",
15 "fx_params": [8000, 8000, 8000, 8000, 8000, 8000, 8000, 8000],
16 "lfo_active": false,
17 "lfo_type": "tremolo",
18 "lfo_params": [16000, 16000, 16000, 16000, 0, 0, 0, 0]
19}
Looks easy enough! There is a start and end and there are 24 points in each array, which I’m guessing will correspond to the 24 keys! I noticed that those numbers are absolutely huge, and if I set an end point to the very end it shows up as 2147483646 - way to big to correspond to the max number of seconds (~12) or milliseconds. I divided that number by the total number of samples - 44100 * 12 - which came out to 4057.98. Thats pretty close to 4058 which seems reasonable (albeit weird) so all I need to do is multiple the sample position by 4058.
*minutes pass*
Turns out I was wrong. Turns out when I did that, it didn’t brick my OP-1 but the markers I thought I had set were completely off. After thinking some more about it I saw that there are a lot of 8192 in the OP-1 JSON data. I’m guessing that this is the smallest number it can discern, so I changed all my markers so that they correspond to the closest multiple of 8192 (max of 13 bits).
And guess what…
It works!
Yes, it works!
So here is how to take any sound and make an OP-1 drum patch with automatic key assignments:
Use ffmpeg to truncate to ~12 seconds and convert a sound to .aif, use ffmpeg to find silence, generate OP-1 JSON using start/end points from silence (careful to only use 13 bits of precision), inject JSON into the .aif file before the SSND tag and update the filler and FORM bytes so its valid.
That’s it! Its short enough to tell someone, not that I knew any of this before starting. And now I can write a program to do this automatically on dozens of samples simultaneously.
My major takeaway from this project is that ffmpeg and xxd are extremely powerful and all I really needed to get my end result. And the best part is that I can run the code on hours of audio which will automatically generate perfect 12-second clips that can be loaded onto the OP-1 with sample key bindings.
And if you want to use my end result, its on the web now at https://teoperator.com and all the source code is available at Github. And if you want to listen to my music, check out my Bandcamp.